機械学習を行う際、欠損データを整理したり、学習データ(特徴量)を変換する必要があります。
例えば年齢情報がない、購入店舗名は文字列なので店舗コードに直す、などです。
本来は標準偏差を調べたり、色々なグラフを作成したりなどしてより深く、特徴量を変換する作業を行う必要があるのですが、どうにも試行錯誤している感が強く、定まったやり方が見つけられなかったので後で勉強することにしてここはざっくり進めます。
ひとまず手っ取り早く学習アルゴリズムの習得に入りたいので、最低限学習できるデータセットに直すことにしました。
手順は以下です。
①特徴量を理解する
②欠損データに対処する
③学習しやすい値に変換する
学習データはKaggleのチュートリアルで多用されるタイタニック号の乗客情報を使います。
※タイタニック号の乗客情報ページ
機械学習環境は過去記事「機械学習の勉強環境を構築する」で構築したものを使用しています。
①特徴量を理解する
(1)データセットの説明などから、各特徴量を理解する
(2)Excelやテキストエディタ、Jupyter notebookで直接データの中身を見る
(3)各特徴量をざっくり理解する
・特徴量は以下12種類
・PassengerId:旅客ID
・Survived:生存情報(0=No, 1=Yes)
・Pclass:チケットクラス(1=1st, 2=2nd, 3=3rd)
・Name:名前
・Sex:性別
・Age:年齢
・SibSp:同乗した兄弟・配偶者の数
・Parch:同乗した親子の数
・Ticket:チケット番号
・Fare:運賃
・Cabin:客室
・Embarked:乗船港(C = Cherbourg, Q = Queenstown, S = Southampton)
(4)データ総数や欠損データ有無を確認する
import pandas
import numpy
import matplotlib
from statsmodels.graphics.mosaicplot import mosaic
import seaborn
# ラベル付きトレーニングデータ読み込み
train_data = pandas.read_csv("train.csv", delimiter=",")
# データ総数(891)
print('【データ総数】\n', train_data.shape[0])
# 欠損データ(NaN)有無(Age, Cabin, Embarkedに欠損データあり)
print('【欠損データ有無】\n', train_data.isnull().any())
# 欠損データ数
print('【欠損データ数】\n', train_data.isnull().sum())
# 以下でnon-null件数、型を表示すると簡単
# train_data.info()
【実行結果】
【データ総数】 891 【欠損データ有無】 PassengerId False Survived False Pclass False Name False Sex False Age True SibSp False Parch False Ticket False Fare False Cabin True Embarked True dtype: bool 【欠損データ数】 PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64
②欠損データに対処する
(1)欠損データへの対処を検討する
・Embarkedに欠損データがある
→ 2/891件と少ないので、NaNのあるデータのみ取り除く
・Cabinに欠損データがある
→ 687/891件と多いので対応が必要だが、そもそもアルファベットと数値の組み合わせを分解するなど、複雑な対応が必要なので今回は保留
・Ageに欠損データがある
→ 177/891件と比較的多いが、代替の値を使えそう
※代替値は欠損を示す値、中央値や平均値、直前のデータの値、0埋めなどの対応がある
年齢欠損における生存率の差があるらしく、欠損を示す値を使っているユーザもいた(過学習になる可能性もあるので今回は除外)
・1行前のデータを複製するのは時系列データの場合なので、今回の乗客データでは不適切
・0埋め(0歳とする)よりは中央値や平均値を使う方がよいと思われる
年齢の欠損値は、データにバラつきがあるなら中央値、バラつきが少ないなら平均値を使うとして、以下のように平均と標準偏差から検討する
(2)欠損データ(年齢)への対処を検討する
print('【年齢:平均値】', train_data['Age'].dropna().mean())
print('【年齢:中央値】', train_data['Age'].dropna().median())
print('【年齢:標準偏差】', train_data['Age'].dropna().std())
print('【年齢:範囲】', train_data['Age'].dropna().min(), '~', train_data['Age'].dropna().max())
train_data['Age'].plot(kind='hist', bins=50, subplots=True);
matplotlib.pyplot.show()
【実行結果】
【年齢:平均値】 29.69911764705882 【年齢:中央値】 28.0 【年齢:標準偏差】 14.526497332334044 【年齢:範囲】 0.42 ~ 80.0
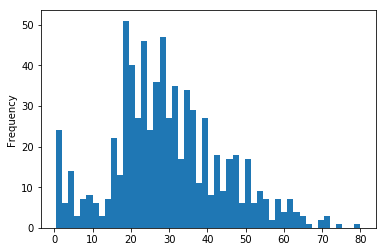
(3)欠損データ(年齢)への対処を決める
平均値と中央値はそれほど大きな差はないが、年齢の最大が80と平均から大きく離れている。そのため、今回は中央値でNaNを埋めることとする
(4)欠損データに対応する
# 欠損データ対応:Embarked
# → 'Embarked'列にNaNを持つデータ行を削除
train_data = train_data.dropna(subset=['Embarked'])
# 欠損データ対応:Age
# → 'Age'列にNaNを持つデータを年齢の中央値に置き換え
train_data_cabin = train_data['Cabin']
train_data = train_data.drop(['Cabin'], axis=1)
train_data = train_data.fillna(train_data.median()['Age'])
train_data['Cabin'] = train_data_cabin
# 欠損データ(NaN)有無(Age, Cabin, Embarkedに欠損データあり)
print('【欠損データ有無】\n', train_data.isnull().any())
print('【データ総数】\n', train_data.shape[0])
# 以下でnon-null件数、型を表示すると簡単
# train_data.info()
【実行結果】
【欠損データ有無】 PassengerId False Survived False Pclass False Name False Sex False Age False SibSp False Parch False Ticket False Fare False Embarked False Cabin True dtype: bool 【データ総数】 889
→Cabinを除き、欠損データが存在しなくなったことが分かる
※AgeのみNaNを中央値に置き換える方法がよく分からなかったため、一旦Cabin列を退避した後で追加
(多分、もっと適切なやり方がある気が。。。)
③学習しやすい値に変換する
ひとまず学習できる状態にすることが目的なので、詳細な特徴エンジニアリングは行わない。単純にラベル化、数値化できない以下のデータは特徴量から除く
(1)単純に扱えない特徴量を見付ける
・Name:名前は単純なラベル化が難しいため、除外
・Ticket:チケット番号は単純な数値以外に何らかの意味を持つデータが含まれており、有用な可能性があるが単純に数値化、ラベル化できないため除外
・Cabin:アルファベットと数値の組み合わせのため加工が必要、除外
(2)単純に扱えない特徴量を列ごと取り除く
train_data = train_data.drop(['Name', 'Ticket', 'Cabin'], axis=1)
(3)性別(Sex)、出発港(Embarked)はそれぞれを新しい列としてバイナリ値で表現する
train_data['male'] = (train_data['Sex'] == 'male').astype(int) train_data['female'] = (train_data['Sex'] == 'female').astype(int) train_data['embarked_c'] = (train_data['Embarked'] == 'C').astype(int) train_data['embarked_q'] = (train_data['Embarked'] == 'Q').astype(int) train_data['embarked_s'] = (train_data['Embarked'] == 'S').astype(int) train_data = train_data.drop(['Sex', 'Embarked'], axis=1)
とりあえず最低限度、学習できるデータセットにする手順でした。本来もっと適切な対応をするべきでしょうが、早く学習アルゴリズムに進むためここまでということで。。。