機械学習を行う際、学習データ(特徴量)を選別する必要があります。
つまり予測結果(目的変数)に対して、特徴量が影響しているかどうかを調べます。
例えば、洋服のメーカーと色、サイズが分かっていて、価格を予測する場合、色という情報は価格に影響するかもしれないししないかもしれません。影響しないことが分かっていれば、学習データから取り除きます。
データをグラフ化することで可視化し、影響の有無を理解します。
私は極力Python環境でグラフ化したいため、Jupyter notebook上で描画を行いました。
今回は以下2つのグラフを作成します。
①モザイク図
②箱ひげ図
学習データはKaggleのチュートリアルで多用されるタイタニック号の乗客情報を使います。
※タイタニック号の乗客情報ページ
機械学習環境は過去記事「機械学習の勉強環境を構築する」で構築したものを使用しています。
■事前準備
(1)ダウンロードした学習データ(train.csv)をWindowsと機械学習環境で共有したフォルダ内に配置
(2)JupyterNotebookのページを開き、共有したフォルダに移動
(3)Python実行ページを開く
①モザイク図
以下のコードを打ち込み、実行します。
# モザイク図(性別/生存情報)
import pandas
import numpy
import matplotlib
from statsmodels.graphics.mosaicplot import mosaic
# ラベル付きトレーニングデータ読み込み
train_data = pandas.read_csv("train.csv", delimiter=",")
# Survived(生存情報)、Sex(性別)のモザイク図
# print(numpy.c_[train_data['Sex'], train_data['Survived']])
engineer_data = numpy.c_[train_data['Sex'], train_data['Survived']]
# DataFrame作成
myDataframe = pandas.DataFrame(engineer_data, columns=['Sex', 'Survived'])
# モザイク図作成、表示
mosaic(data=myDataframe, index=['Sex', 'Survived'], title='Mosaic Plot')
matplotlib.pyplot.show()
実行結果は以下のグラフになります。
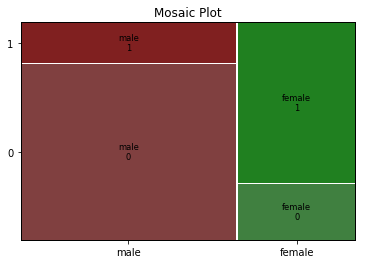
1が生存、0が死亡を表しており、茶色が男性(male)、緑が女性(female)を表しています。乗客には男性の方が多く、女性の方がより生存していることが分かります。
よって、性別(Sex)情報は特徴量に用いるべきと判断できます。
色々とデータを切り替えて、各データをグラフ化してみると以下のようになります。
■モザイク図(チケットランク/生存情報)
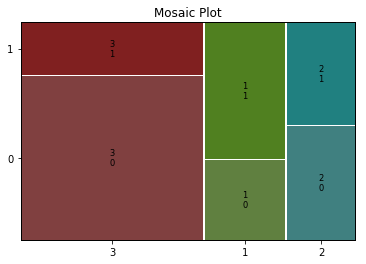
チケットランクは経済的情報の代わりに使用するとあり、3(上位)、2(中位)、1(下位)となります。富裕の度合いに応じた生存情報(1:生存、2:死亡)が確認できます。
■モザイク図(乗船港/生存情報)
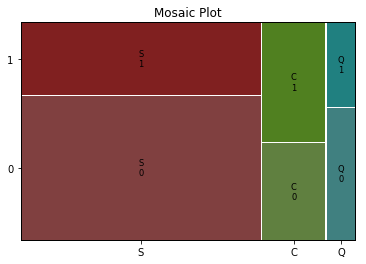
乗船港は、C(Cherbourg)、Q(Queenstown)、S(Southampton)として生存情報(1:生存、2:死亡)を確認します。
モザイク図にはPythonの統計用ライブラリstatsmodelsを使用しています。
statsmodelsのマニュアルページ
表示する順番とか色々変えたいのですが、今のところよく分からず。時間がある時にもうちょっと詳しく調べたいと思います。
②箱ひげ図
同様にJupyter Notebook上で以下のコードを打ち込み、実行します。
# 箱ひげ図(年齢/生存情報)
import pandas
import numpy
import matplotlib
from statsmodels.graphics.mosaicplot import mosaic
# ラベル付きトレーニングデータ読み込み
train_data = pandas.read_csv("train.csv", delimiter=",")
# 生存した乗客の年齢情報抽出
survived_data = train_data[train_data.Survived == 1]['Age']
# 死亡した乗客の年齢情報抽出
dead_data = train_data[train_data.Survived == 0]['Age']
# リスト化 & 欠損データ(NaN)削除
survived_data = survived_data.dropna(how='all').values.tolist()
dead_data = dead_data.dropna(how='all').values.tolist()
# 箱ひげ図用にデータを二次元化
beard = (survived_data, dead_data)
# 新規ウィンドウ作成
fig = matplotlib.pyplot.figure()
# 新規グラフ描画領域作成
ax = fig.subplots()
# 箱ひげ図作成
bp = ax.boxplot(beard)
# ラベル付与
ax.set_xticklabels(['Survived', 'Dead'])
# グラフの詳細設定
# タイトル
matplotlib.pyplot.title('Box plot')
# グリッド
matplotlib.pyplot.grid()
# X軸名
matplotlib.pyplot.xlabel('Survived')
# Y軸名
matplotlib.pyplot.ylabel('Age')
# Y軸の幅(0~100)
matplotlib.pyplot.ylim([0,100])
# グラフ描画
matplotlib.pyplot.show()
実行結果は以下のグラフになります。
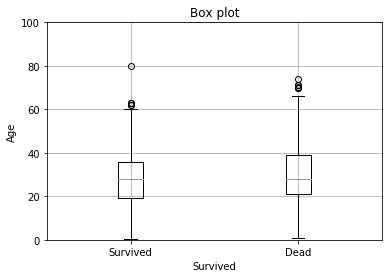
箱ひげの見方ですが、箱の中央の赤い横線が中央値です。同様に中央値の計算を使って箱と髭(線)を作成しており、大幅に外れている値が外れ値(〇でプロットされたデータ)です。
データ(年齢)に欠損データ(NaN)が含まれているとグラフ化できなかったため、取り除いています。欠損データの取り扱いやデータ加工(特徴エンジニアリング)については、以下の書籍に色々と書いてあります。
イマイチ箱ひげ図の活用方法を理解していないのでざっくりした感じになりますが、予測結果(生存情報)ごとに表示した左右の箱ひげ図の形が違う場合は学習に用いるべきと判断することになるようです。また外れ値が多い場合はデータの大きさを調整します。(平方根や対数にする、など)
上記の他、密度図や散布図も使うようです。必要になったらまた調べる予定ですが、散布図はともかく密度図は何となく作るのが大変そうな予感。