オープンソースのAIコンテナ、つまりdocker環境下で動作するAIアプリを仮想マシンごと(コンテナとして)取得して動かす方法です。
RESTプログラムが動作するだけなのでプログラミングは不要。curlコマンドでHTTP要求を確認するだけなので、私はPOSTMANを使って確認しました。
スマホで偶然見た記事が気になり、興味があったので動かしてみました。
参考URL:IBMテクノロジーの“認定インフルエンサー”、「IBM Champions」からのメッセージ
まずIBM MAX(IBM Model Asset eXchange)について。
IBMのWatsonビルを拠点とするデータサイエンティストとオープンソース技術者のグループCODAITが作成したAIコンテナです。
学習済みモデルを使ったREST(Web API)アプリが動作するコンテナをオープンソースとして提供してくれています。
現時点(2019/5)で公開されているコンテナは30種類ありましたが、ひとまずは記事にあった以下6種類のコンテナを動かしてみました。
(1)ImageCaptionGenerator: 画像に写ったものの説明文を生成する
(2)FacialRecognizer: 顔を含む画像について、顔の位置情報を取得する
(3)FacialAgeEstimator: 顔画像から年齢を推定する
(4)ImageColorizer: 白黒画像をカラー画像に変換する
(5)ObjectDetector: 画像に写ったオブジェクトの名前を取得する
(6)AudioClassifier: 音声データから何の音かを判定する
前提となる環境と、それぞれのコンテナの精度及びおおまかな使い方について記します。
■前提環境(Windows環境なので代替ツールを使用)
・Docker(Docker ToolBox)
・curl(POSTMAN)
■注意点
基本的には説明ページの手順通りで動作します。ただしWindows環境(Docker Toolbox)におけるHTTP要求先は「http://localhost:5000/model/predict」ではなく、「http://192.168.99.100:5000/model/predict」になるかと思います。
説明ページの手順ではlocalhostつまりローカルマシン(Linux環境)で直接Dockerを動かしている想定になっています。docker toolboxでは仮想マシンdefaultというlinux環境でdockerを動かしているので、localhostの代わりにdefaultのIPアドレスである192.168.99.100を指定してアクセスします。
(1)ImageCaptionGenerator: 画像に写ったものの説明文を生成する
説明ページ
・docker ToolboxのDocker Quickstart Terminalを起動して、以下のコマンドを実行。
docker run -dit -p 5000:5000 codait/max-image-caption-generator
※オプション-dを追加したのはバックグラウンドで動かすため
※環境によってダウンロードにしばらく時間がかかる
・POSTMANでHTTPメソッドを「PUT」、URLを「http://192.168.99.100:5000/model/predict」に設定し、
BODYタブのKEYの空欄右端を選択し、「File」と「Text」のドロップダウンリストが表示されたら「File」を選択する。
VALUEの空欄に表示される「Select Files」を押して、任意の画像を選択する。KEYの空欄に「image」と記述する。
Sendボタンを押す。
・docker ToolboxのDocker Quickstart Terminalで全コンテナ停止
docker stop $(docker ps -q)
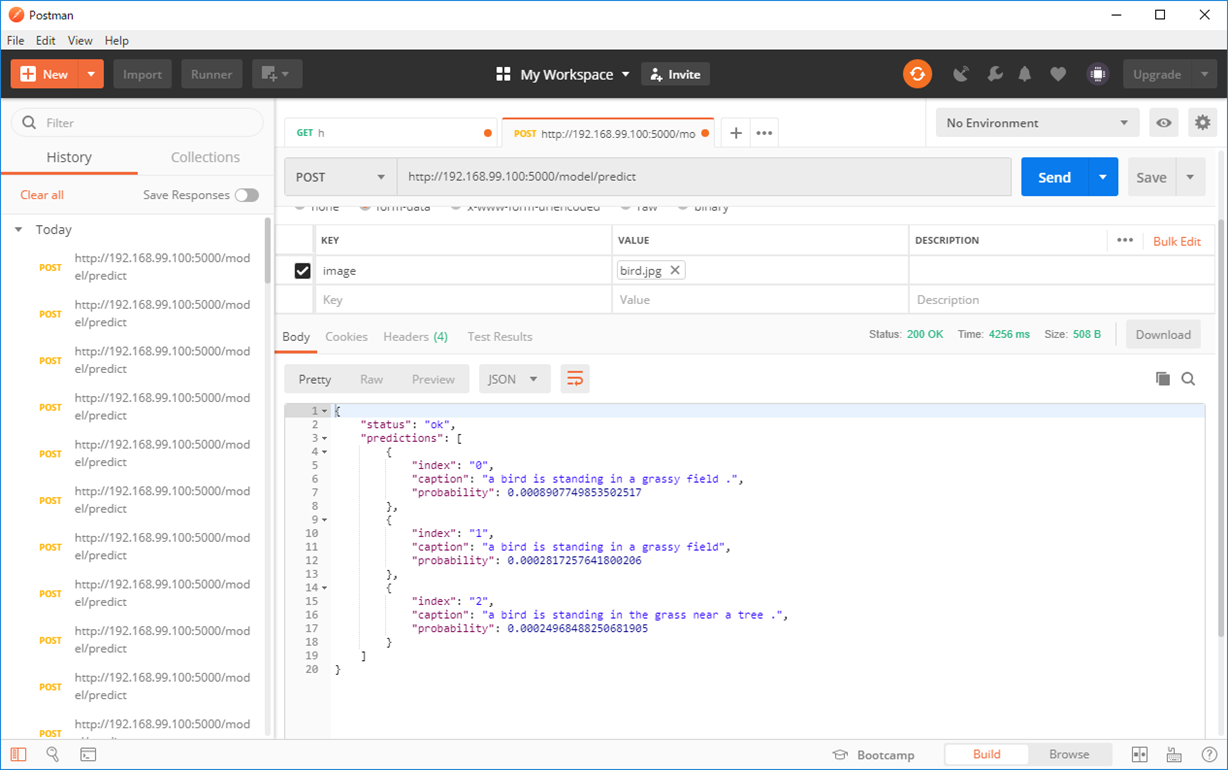
草原をバックにした鳥の画像を入力したところ、「a bird is standing in a grassy field.」(草原に鳥が立っている)という結果が返ってきました。かなりいい感じです。
(2)FacialRecognizer: 顔を含む画像について、顔の位置情報を取得する
説明ページ
・docker ToolboxのDocker Quickstart Terminalを起動して、以下のコマンドを実行。
docker run -dit -p 5000:5000 codait/max-facial-recognizer
※オプション-dを追加したのはバックグラウンドで動かすため
※環境によってダウンロードにしばらく時間がかかる
・POSTMANでHTTPメソッドを「PUT」、URLを「http://192.168.99.100:5000/model/predict」に設定し、
BODYタブのKEYの空欄右端を選択し、「File」と「Text」のドロップダウンリストが表示されたら「File」を選択する。
VALUEの空欄に表示される「Select Files」を押して、任意の画像を選択する。KEYの空欄に「image」と記述する。
Sendボタンを押す。

・docker ToolboxのDocker Quickstart Terminalで全コンテナ停止
docker stop $(docker ps -q)
位置を確認していませんが、顔は中央上方にある画像だったので、概ね良さそうな感じです。
(3)FacialAgeEstimator: 顔画像から年齢を推定する
説明ページ
・docker ToolboxのDocker Quickstart Terminalを起動して、以下のコマンドを実行。
docker run -dit -p 5000:5000 codait/max-facial-age-estimator
※オプション-dを追加したのはバックグラウンドで動かすため
※環境によってダウンロードにしばらく時間がかかる
・POSTMANでHTTPメソッドを「PUT」、URLを「http://192.168.99.100:5000/model/predict」に設定し、
BODYタブのKEYの空欄右端を選択し、「File」と「Text」のドロップダウンリストが表示されたら「File」を選択する。
VALUEの空欄に表示される「Select Files」を押して、任意の画像を選択する。KEYの空欄に「image」と記述する。
Sendボタンを押す。

・docker ToolboxのDocker Quickstart Terminalで全コンテナ停止
docker stop $(docker ps -q)
30代中盤の男性の画像ですが、24歳と表示されました。80歳を超えた老人は59歳と表示されたので、日本人の顔は判定が微妙なのかもしれません。赤子が29歳なのはちょっとどうかと思いますが……ちょっと精度は良くないかもしれません。
ちなみにAWSの同様のシステムでも同じく80歳を超えた老人の画像を読み込ませたところ、57~77歳と出力されました。
(4)ImageColorizer: 白黒画像をカラー画像に変換する
説明ページ
・docker ToolboxのDocker Quickstart Terminalを起動して、以下のコマンドを実行。
docker run -dit -p 5000:5000 codait/max-image-colorizer
※オプション-dを追加したのはバックグラウンドで動かすため
※環境によってダウンロードにしばらく時間がかかる
・POSTMANでHTTPメソッドを「PUT」、URLを「http://192.168.99.100:5000/model/predict」に設定し、
BODYタブのKEYの空欄右端を選択し、「File」と「Text」のドロップダウンリストが表示されたら「File」を選択する。
VALUEの空欄に表示される「Select Files」を押して、任意の画像を選択する。KEYの空欄に「image」と記述する。
Sendボタンを押す。
・docker ToolboxのDocker Quickstart Terminalで全コンテナ停止
docker stop $(docker ps -q)
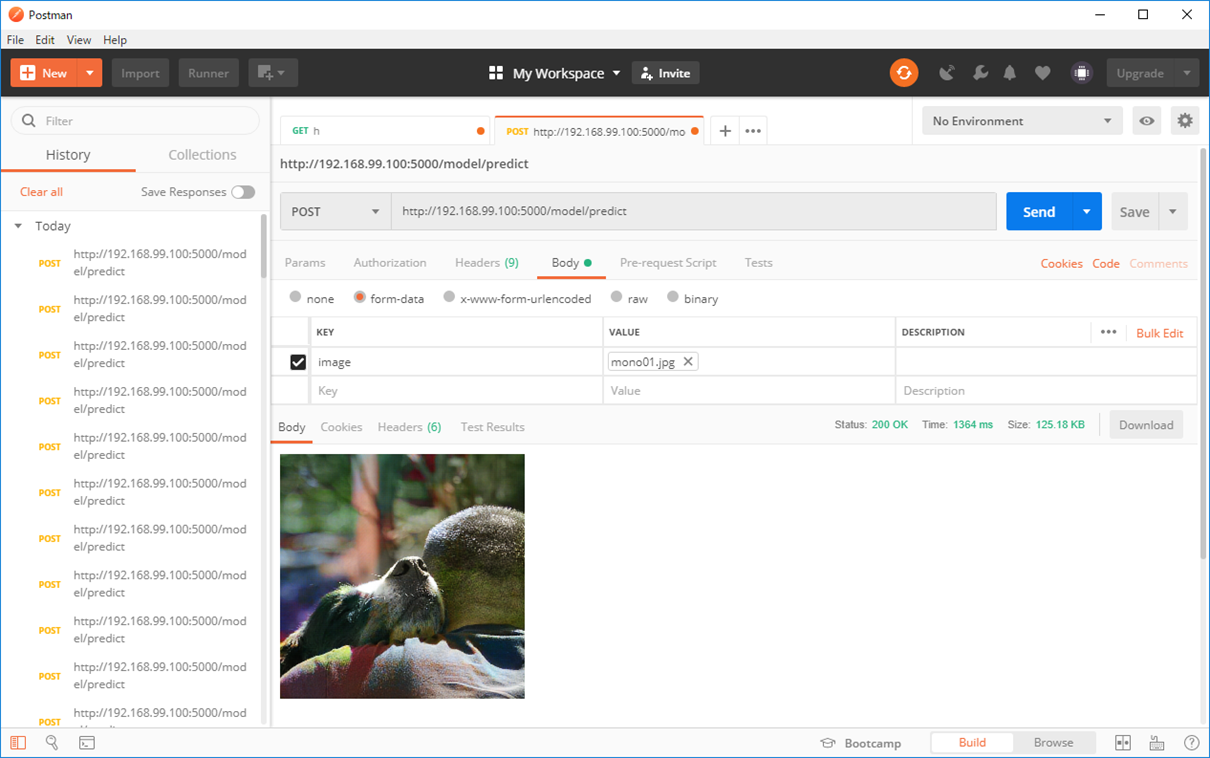
フリーの画像で、犬と抱き合う男性の画像を読み込ませてみました。他にも色々と読み込ませてみましたが、同じように色が滲む感じでカラーっぽくなる程度です。上記のキャプチャで、何となく雰囲気は伝わるかと思います。
(5)ObjectDetector: 画像に写ったオブジェクトの名前を取得する
説明ページ
・docker ToolboxのDocker Quickstart Terminalを起動して、以下のコマンドを実行。
docker run -dit -p 5000:5000 codait/max-object-detector
※オプション-dを追加したのはバックグラウンドで動かすため
※環境によってダウンロードにしばらく時間がかかる
・POSTMANでHTTPメソッドを「PUT」、URLを「http://192.168.99.100:5000/model/predict」に設定し、
BODYタブのKEYの空欄右端を選択し、「File」と「Text」のドロップダウンリストが表示されたら「File」を選択する。
VALUEの空欄に表示される「Select Files」を押して、任意の画像を選択する。KEYの空欄に「image」と記述する。
Sendボタンを押す。
・docker ToolboxのDocker Quickstart Terminalで全コンテナ停止
docker stop $(docker ps -q)
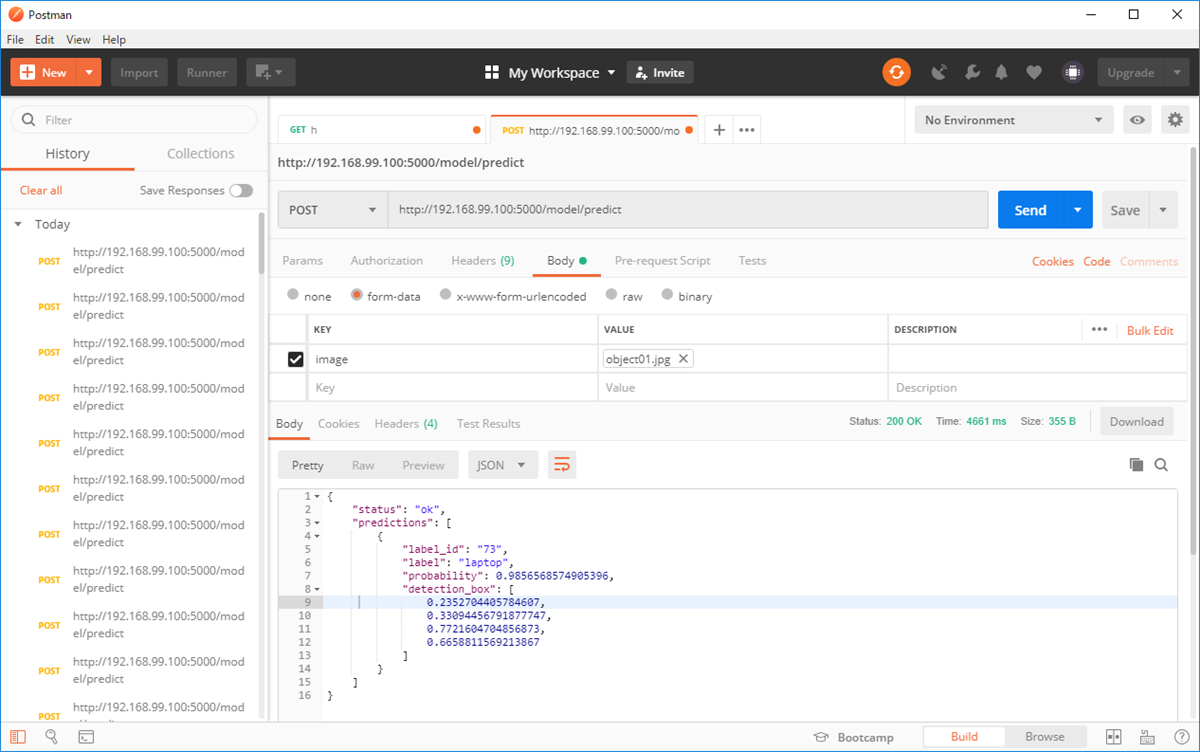
フリーの画像で、テーブル中央にノートパソコン、その周囲にスマホやマグカップ、手帳などが置かれている画像を使いました。最も目立つノートパソコンはしっかり認識してくれていますが、その他の道具については情報がありませんでした。一番目立つものはしっかり理解してくれているので、まあいい感じではないでしょうか。
(6)AudioClassifier: 音声データから何の音かを判定する
説明ページ
・docker ToolboxのDocker Quickstart Terminalを起動して、以下のコマンドを実行。
docker run -dit -p 5000:5000 codait/max-object-detector
※オプション-dを追加したのはバックグラウンドで動かすため
※環境によってダウンロードにしばらく時間がかかる
・POSTMANでHTTPメソッドを「PUT」、URLを「http://192.168.99.100:5000/model/predict」に設定し、
BODYタブのKEYの空欄右端を選択し、「File」と「Text」のドロップダウンリストが表示されたら「File」を選択する。
VALUEの空欄に表示される「Select Files」を押して、任意の音声ファイルを選択する。KEYの空欄に「audio」と記述する。
Sendボタンを押す。
・docker ToolboxのDocker Quickstart Terminalで全コンテナ停止
docker stop $(docker ps -q)
これがまた確認に苦労しました。音声ファイルはエンコード等で色々制限があるだろうなと思っていましたが、エラーメッセージから「signed 16-bit PCM WAV audio file(16ビット署名付きPCM WAVファイル)」の音声ファイルでなければいけないようです。
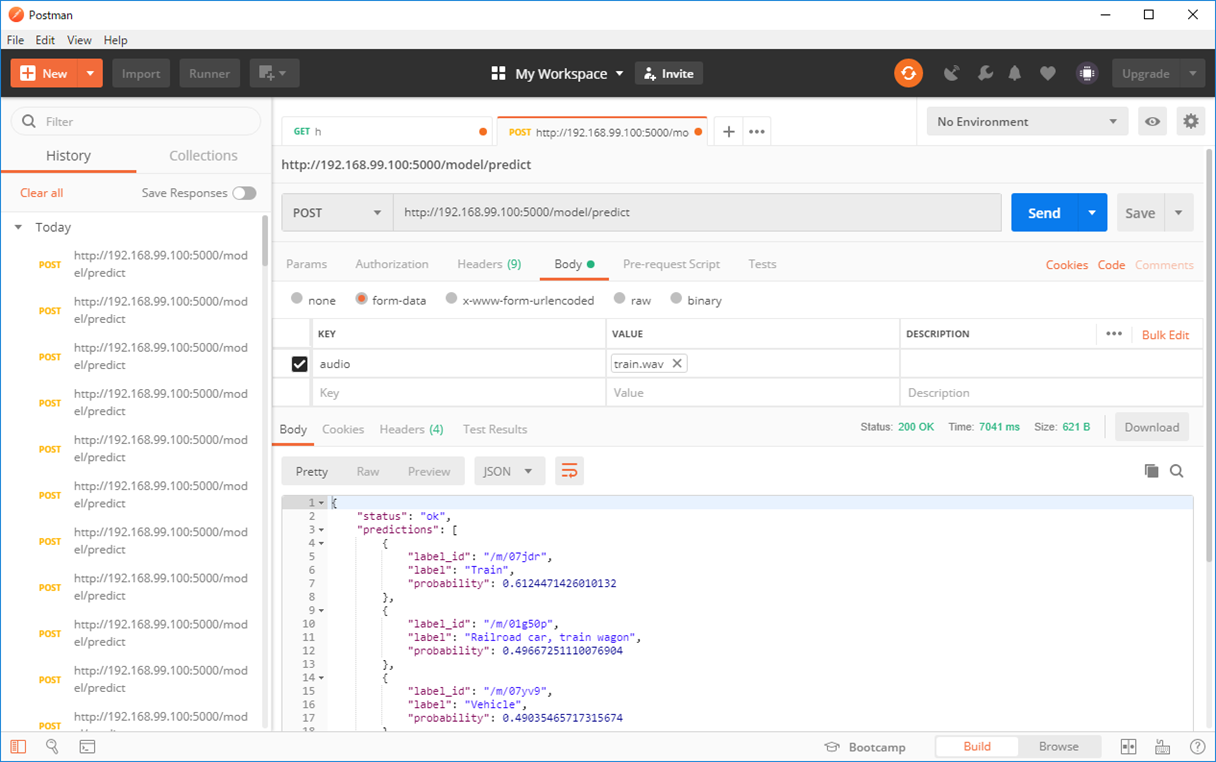
とりあえず適当にmp3音源をWAVに変換するなどして確認しました。注意点としては、音声ファイルの拡張子は小文字で「.wav」でなければいけない点と、動物の泣き声などは認識できないのかInternal Server Errorが返ってきます。手持ちのファイルでは、キャプチャの電車の通過音はしっかり認識してくれました。
音声ファイルの形式や長さなどに問題があるのかもしれませんし、判定を想定しているのが生活音等なのかもしれません。このコンテナは精度が良いのかどうか悩ましいところです。
とりあえず一通り動かした感想としては、クラウド上の有料サービスには劣るものの、dockerの起動・停止などができればかなり簡単に動かすことができるので、お手軽にAI環境を構築できる良いものだと思います。
IBMMAXを利用したWEBアプリ等はIBMコードパターンのサイトで確認できるので、時間があったら少し見てみようと思います。